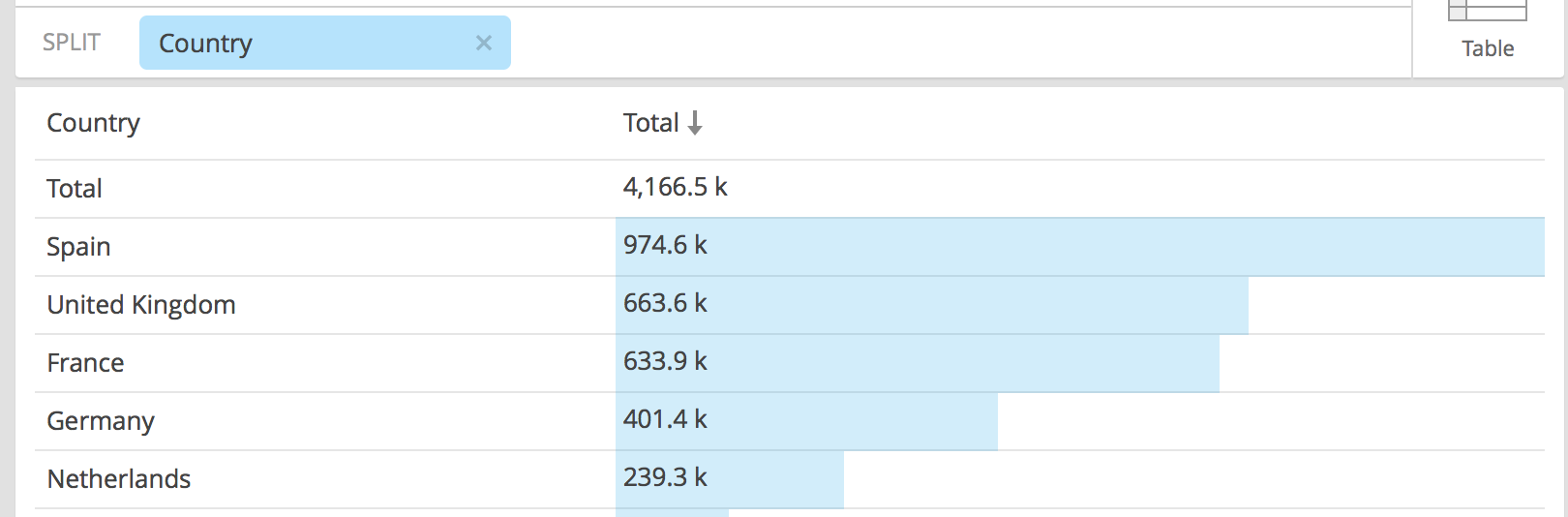
I'm doing a simple query for data from a Druid database, and the results I get differ from the ones present in the dataset, which are consistent with the ones I get with Pivot.
Spark SQL query on source data:
select Country,COUNT(*) AS count from AllUsers GROUP BY country ORDER by count DESC LIMIT 5;
Spain 974613
United Kingdom 663602
France 633858
Germany 401395
Netherlands 239266