Hi,
We’ve been using v0.36.4 for 3 weeks now in the company and it eliminated our previous issue with v0.33.3 on metabase getting stuck randomly needing us to hard restart it every time. Today, we just encountered this very similar issue twice and my guess is that it has something to do with our new slow dashboard.
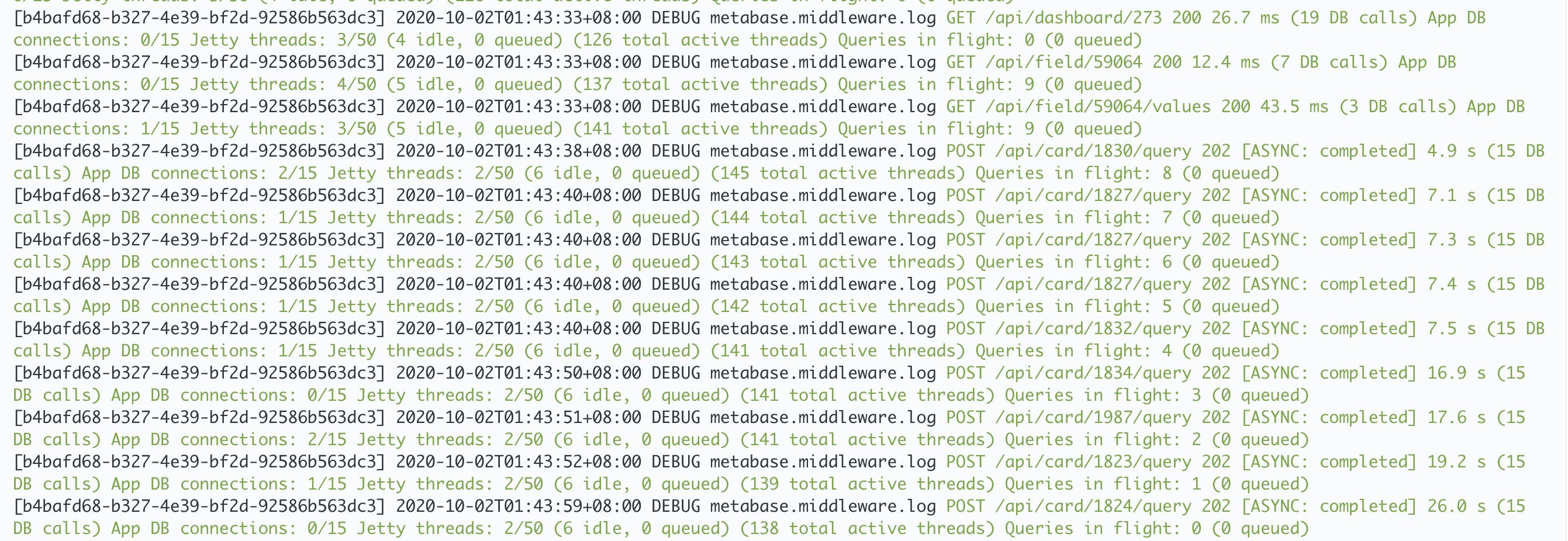
During the issue, this is how the logs looks like:
[581a0491-fc85-47c3-bbe4-60422d2642ea] 2020-10-01T16:41:13+08:00 DEBUG metabase.middleware.log GET /api/database 200 348.6 ms (4 DB calls) App DB connections: 0/15 Jetty threads: 20/50 (14 idle, 0 queued) (381 total active threads) Queries in flight: 50 (8 queued)
No query are being executed o our Redshift Data Warehouse and only a hard restart of the metabase docker-container fixed it.
As far as I know, this is a problem with our metabase set-up and I want to consult you guys on several things for me to figure out how to scale metabase on our end.
- How to read the logs above?
0/15 APP DB connections - 0 connections on Metabase Postgres DB
20/50 Jetty Threads - I assume this is the connection thread going to our Redshift instance? I’ve used the environment variable MB_JDBC_DATA_WAREHOUSE_MAX_CONNECTION_POOL_SIZE to configure it to 50.
381 total active threads - I don’t have any idea about this.
50 queries in flight - Metabase thinks that it’s currently running 50 queries even though nothing is appearing in Redshift. But not sure how is this related to 381 total active threads or even at 20/50 jetty threads.
8 queued - I’m assuming here that 50 queries in flight is the maximum for metabase and any new requests will be queued and in this case it’s 8.
- Is there any way for me to increase the maximum queries in flight? Increase memory? Increase CPU? Or is it just better to horizontally scale in this case?
Diagnostic Info:
{
"browser-info": {
"language": "en",
"platform": "MacIntel",
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Safari/605.1.15",
"vendor": "Apple Computer, Inc."
},
"system-info": {
"file.encoding": "UTF-8",
"java.runtime.name": "OpenJDK Runtime Environment",
"java.runtime.version": "11.0.8+10",
"java.vendor": "AdoptOpenJDK",
"java.vendor.url": "https://adoptopenjdk.net/",
"java.version": "11.0.8",
"java.vm.name": "OpenJDK 64-Bit Server VM",
"java.vm.version": "11.0.8+10",
"os.name": "Linux",
"os.version": "5.3.0-1035-aws",
"user.language": "en",
"user.timezone": "Asia/Kuala_Lumpur"
},
"metabase-info": {
"databases": [
"postgres",
"redshift"
],
"hosting-env": "unknown",
"application-database": "postgres",
"application-database-details": {
"database": {
"name": "PostgreSQL",
"version": "9.6.14"
},
"jdbc-driver": {
"name": "PostgreSQL JDBC Driver",
"version": "42.2.8"
}
},
"run-mode": "prod",
"version": {
"date": "2020-08-17",
"tag": "v0.36.4",
"branch": "release-0.36.x",
"hash": "196c1f6"
},
"settings": {
"report-timezone": "Asia/Kuala_Lumpur"
}
}
}
Hardware:
- Single AWS EC2 instance m5a.large
- Docker Container
- 2 cores, 8gb memory
Environment Variables:
- JAVA_TIMEZONE: Asia/Kuala_Lumpur
- JAVA_TOOL_OPTIONS: -Xmx6g
- MB_JDBC_DATA_WAREHOUSE_MAX_CONNECTION_POOL_SIZE: 30
We’ve also turned off caching for now because of https://github.com/metabase/metabase/issues/13164.
Sorry for the lengthy post and thanks in advanced!
 on the first post
on the first post