I’ve had success setting up MB on the Mac App, however the AWS ElasticBeanstalk process is giving me some trouble.
Everything seems to go fine until the end. The environment healths transitions from Pending to Severe, where it hangs for around 10 mins before giving 2 errors.
2015-10-25 11:57:07 UTC+0000 ERROR Stack named 'awseb-e-ngyt8icgae-stack' aborted operation. Current state: 'CREATE_FAILED' Reason: The following resource(s) failed to create: [AWSEBInstanceLaunchWaitCondition].
2015-10-25 11:56:50 UTC+0000 ERROR The EC2 instances failed to communicate with AWS Elastic Beanstalk, either because of configuration problems with the VPC or a failed EC2 instance. Check your VPC configuration and try launching the environment again.
2015-10-25 11:36:17 UTC+0000 WARN Environment health has transitioned from Pending to Severe. None of the instances are sending data.
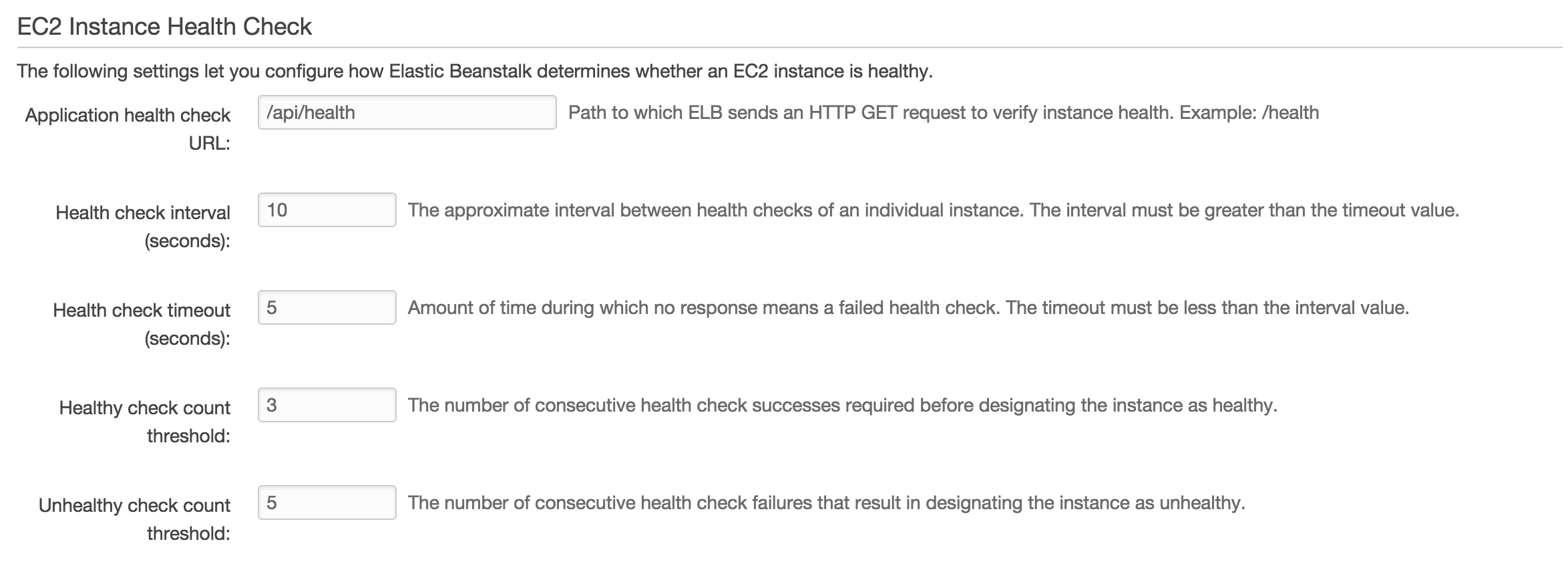
Some digging around has posed the question, what should the health check type be: 1) Basic; or 2) Enhanced. Some suggestions only point to Enhanced being an issue? I’ve tried both.
I’m not entirely sure of the differences but the documentation doesn’t allude to which should be selected. Enhanced is selected by default.
I’ve tried to check my security groups and VPC settings, and traffic should be fine, but I can’t SSH in to the EB instance.
I’m creating this EB application in EU region, so I’ve had to download MB and upload it rather than insert the S3 URL. Other than this, I’ve followed the guide, adding my key-pair and setting my VPC settings.
Update:
Triple checked VPC settings. Only errors I get now are:
2015-10-25 13:14:17 UTC+0000 ERROR Stack named 'awseb-e-jafkwqspnv-stack' aborted operation. Current state: 'CREATE_FAILED' Reason: The following resource(s) failed to create: [AWSEBInstanceLaunchWaitCondition].
2015-10-25 13:14:04 UTC+0000 ERROR The EC2 instances failed to communicate with AWS Elastic Beanstalk, either because of configuration problems with the VPC or a failed EC2 instance. Check your VPC configuration and try launching the environment again.