I get the following error and I don't know why, My database is sparksql, when I using field fitter in Native query,
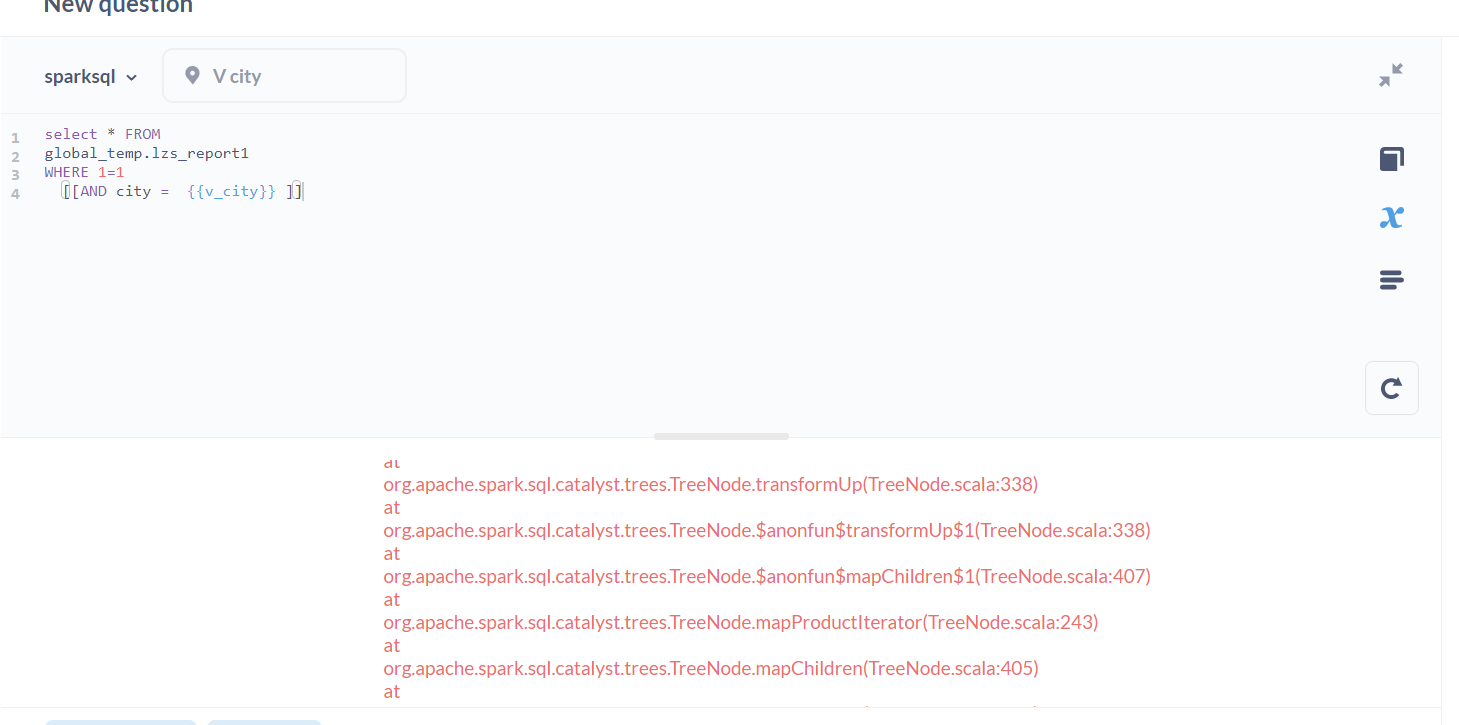
org.apache.hive.service.cli.HiveSQLException: Error running query: org.apache.spark.sql.AnalysisException: cannot resolve '
dim_city.d_city' given input columns: [global_temp.lzs_report1.AREA_TYPE, global_temp.lzs_report1.AREA_TYPE_EXT, global_temp.lzs_report1.CUST_TYPE4, global_temp.lzs_report1.SALE_SCOPE, global_temp.lzs_report1.base_type, global_temp.lzs_report1.city, global_temp.lzs_report1.down, global_temp.lzs_report1.flat, global_temp.lzs_report1.organ_name, global_temp.lzs_report1.up]; line 5 pos 14; 'Project [] +- 'Filter ((1 = 1) AND (city#31327 = 'dim_city.d_city) IN (decode(unhex(e4b89ce88e9ee5b882), utf-8))) +- SubqueryAlias global_temp.lzs_report1 +- Relation[city#31327,organ_name#31328,base_type#31329,SALE_SCOPE#31330,AREA_TYPE#31331,AREA_TYPE_EXT#31332,CUST_TYPE4#31333,up#31334L,flat#31335L,down#31336L] JDBCRelation(aggregation.lzs_report1) [numPartitions=1] at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.org$apache$spark$sql$hive$thriftserver$SparkExecuteStatementOperation$$execute(SparkExecuteStatementOperation.scala:361) at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$anon$2$$anon$3.$anonfun$run$2(SparkExecuteStatementOperation.scala:263) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at org.apache.spark.sql.hive.thriftserver.SparkOperation.withLocalProperties(SparkOperation.scala:78) at org.apache.spark.sql.hive.thriftserver.SparkOperation.withLocalProperties$(SparkOperation.scala:62) at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.withLocalProperties(SparkExecuteStatementOperation.scala:43) at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$anon$2$$anon$3.run(SparkExecuteStatementOperation.scala:263) at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$anon$2$$anon$3.run(SparkExecuteStatementOperation.scala:258) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1746) at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$anon$2.run(SparkExecuteStatementOperation.scala:272) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: org.apache.spark.sql.AnalysisException: cannot resolve 'dim_city.d_city' given input columns: [global_temp.lzs_report1.AREA_TYPE, global_temp.lzs_report1.AREA_TYPE_EXT, global_temp.lzs_report1.CUST_TYPE4, global_temp.lzs_report1.SALE_SCOPE, global_temp.lzs_report1.base_type, global_temp.lzs_report1.city, global_temp.lzs_report1.down, global_temp.lzs_report1.flat, global_temp.lzs_report1.organ_name, global_temp.lzs_report1.up]; line 5 pos 14; 'Project [] +- 'Filter ((1 = 1) AND (city#31327 = 'dim_city.d_city) IN (decode(unhex(e4b89ce88e9ee5b882), utf-8))) +- SubqueryAlias global_temp.lzs_report1 +- Relation[city#31327,organ_name#31328,base_type#31329,SALE_SCOPE#31330,AREA_TYPE#31331,AREA_TYPE_EXT#31332,CUST_TYPE4#31333,up#31334L,flat#31335L,down#31336L] JDBCRelation(aggregation.lzs_report1) [numPartitions=1] at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:42) at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$$nestedInanonfun$checkAnalysis$1$2.applyOrElse(CheckAnalysis.scala:155) at org.apache.spark.sql.catalyst.analysis.CheckAnalysis$$anonfun$$nestedInanonfun$checkAnalysis$1$2.applyOrElse(CheckAnalysis.scala:152) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformUp$2(TreeNode.scala:341) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:73) at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:341) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformUp$1(TreeNode.scala:338) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$mapChildren$1(TreeNode.scala:407) at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:243) at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:405) at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:358) at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:338) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformUp$1(TreeNode.scala:338) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$mapChildren$1(TreeNode.scala:407) at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:243) at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:405) at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:358) at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:338) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformUp$1(TreeNode.scala:338) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$mapChildren$1(TreeNode.scala:407) at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:243) at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:405) at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:358) at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:338) at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$transformExpressionsUp$1(QueryPlan.scala:104) at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$mapExpressions$1(QueryPlan.scala:116) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:73) at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpression$1(QueryPlan.scala:116) at org.apache.spark.sql.catalyst.plans.QueryPlan.recursiveTransform$1(QueryPlan.scala:127) at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$mapExpressions$4(QueryPlan.scala:137) at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:243) at org.apache.spark.sql.catalyst.plans.QueryPlan.mapExpressions(QueryPlan.scala:137) at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpressionsUp(QueryPlan.scala:104) at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.$anonfun$checkAnalysis$1(CheckAnalysis.scala:152) at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.$anonfun$checkAnalysis$1$adapted(CheckAnalysis.scala:93) at org.apache.spark.sql.catalyst.trees.TreeNode.foreachUp(TreeNode.scala:183) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$foreachUp$1(TreeNode.scala:182) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$foreachUp$1$adapted(TreeNode.scala:182) at scala.collection.immutable.List.foreach(List.scala:392) at org.apache.spark.sql.catalyst.trees.TreeNode.foreachUp(TreeNode.scala:182) at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.checkAnalysis(CheckAnalysis.scala:93) at org.apache.spark.sql.catalyst.analysis.CheckAnalysis.checkAnalysis$(CheckAnalysis.scala:90) at org.apache.spark.sql.catalyst.analysis.Analyzer.checkAnalysis(Analyzer.scala:155) at org.apache.spark.sql.catalyst.analysis.Analyzer.$anonfun$executeAndCheck$1(Analyzer.scala:176) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:228) at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:173) at org.apache.spark.sql.execution.QueryExecution.$anonfun$analyzed$1(QueryExecution.scala:73) at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:111) at org.apache.spark.sql.execution.QueryExecution.$anonfun$executePhase$1(QueryExecution.scala:143) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772) at org.apache.spark.sql.execution.QueryExecution.executePhase(QueryExecution.scala:143) at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:73) at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:71) at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:63) at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:98) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772) at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:96) at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:615) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772) at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:610) at org.apache.spark.sql.SQLContext.sql(SQLContext.scala:650) at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.org$apache$spark$sql$hive$thriftserver$SparkExecuteStatementOperation$$execute(SparkExecuteStatementOperation.scala:325) ... 16 more