Hello. I am trying to decouple my RDS database and create a new EB environment to run 0.40, but I keep failing. I would really appreciate some help! Here is what I have done:
-
https://www.metabase.com/docs/latest/operations-guide/creating-RDS-database-on-AWS.html#decouple-your-rds-database-from-the-elastic-beanstalk-deployment Decoupled the database using this guide, but I did not terminate the old environment. I created a snapshot of my database, and then I "restored" the snapshot to create a new db in RDS. (The snapshot is from Metabase running 0.39.4.)
- I could not do this:
Enter metabase as the Initial database namebecause the "initial database name" field was not there.
- I could not do this:
-
https://www.metabase.com/docs/latest/operations-guide/running-metabase-on-elastic-beanstalk.html Created a new EB environment with platform branch "Docker running on 64bit Amazon Linux 2" version 3.4.2 with the settings noted in the guide: health check path, the same VPC as the new RDS db with two zones for load balancer subnets and one for instance subnets, and load balancer from 4 to 1.
-
I edited the security group settings of the RDS database. When I edit "CIDR/IP - Inbound" security rules, I saw PostgreSQL but when I tried to remove the IP address and add the group ID of my new EB environment I got an error:
You may not specify a referenced group id for an existing IPv4 CIDR rule.So instead I added a new rule with the group ID and left the other one with the IP address alone. -
After the environment finished building, Metabase was accessible but runs me through the setup. So I tried to connect it to the RDS database I created from the snapshot. I added the following environment variables:
-
MB_DB_DBNAMEI tried "metabase", the DB identifier name in RDS, and leaving it out -
MB_DB_HOSTwith the endpoint shown on the RDS db -
MB_DB_PASSwith the password -
MB_DB_USERwith the username -
MB_DB_TYPEwith value "postgres" -
MB_DB_PORTwith value 5432
-
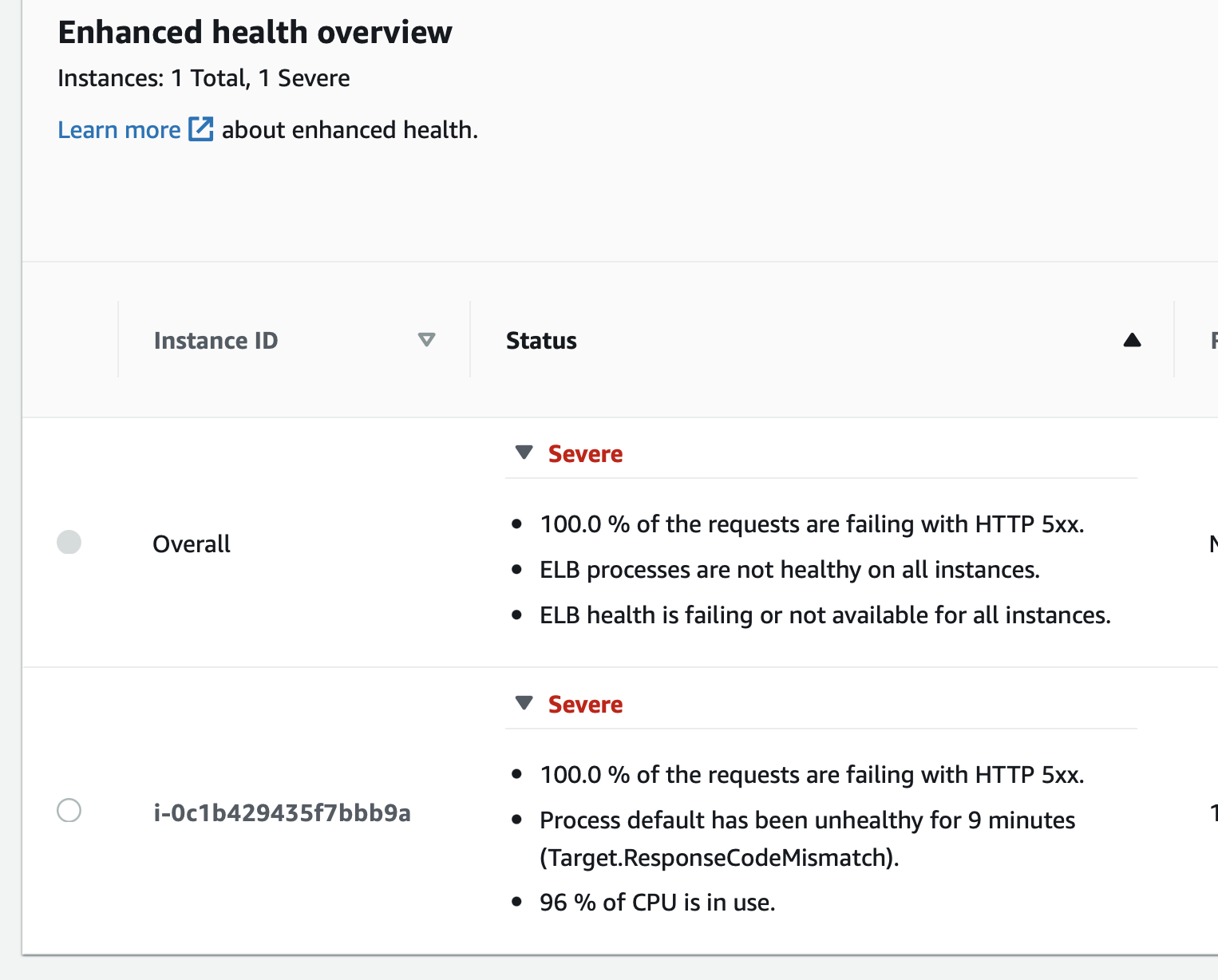
But I got the following errors when I tried to apply the configuration:
| Time | Type | Details |
|---|---|---|
| 2021-07-20 19:45:41 UTC-0700 | ERROR | Failed to deploy configuration. |
| 2021-07-20 19:45:41 UTC-0700 | ERROR | Unsuccessful command execution on instance id(s) 'i-0d3202972532132e4'. Aborting the operation. |
| 2021-07-20 19:45:41 UTC-0700 | INFO | Command execution completed on all instances. Summary: [Successful: 0, Failed: 1]. |
| 2021-07-20 19:45:40 UTC-0700 | ERROR | [Instance: i-0d3202972532132e4] Command failed on instance. Return code: 1 Output: Engine execution has encountered an error.. |
| 2021-07-20 19:45:40 UTC-0700 | ERROR | Instance deployment failed to build the Docker image. The deployment failed. |
2021/07/21 02:45:35.901913 [INFO] successfully execute command: docker pull metabase/metabase:v0.40.1
2021/07/21 02:45:35.901936 [INFO] successfully pulled docker image metabase/metabase:v0.40.1
2021/07/21 02:45:35.901941 [INFO] start to build docker image
2021/07/21 02:45:35.918658 [INFO] Running command /bin/sh -c docker build -t aws_beanstalk/staging-app /var/app/staging/
2021/07/21 02:45:37.958202 [INFO] Sending build context to Docker daemon 24.58kB
2021/07/21 02:45:37.960456 [WARN] failed to execute command: docker build -t aws_beanstalk/staging-app /var/app/staging/, retrying...
2021/07/21 02:45:37.965955 [INFO] Running command /bin/sh -c docker build -t aws_beanstalk/staging-app /var/app/staging/
2021/07/21 02:45:40.196729 [INFO] Sending build context to Docker daemon 24.58kB
2021/07/21 02:45:40.200741 [ERROR] An error occurred during execution of command [config-deploy] - [Docker Specific Build Application]. Stop running the command. Error: failed to build docker image: Command /bin/sh -c docker build -t aws_beanstalk/staging-app /var/app/staging/ failed with error exit status 1. Stderr:Error response from daemon: Error processing tar file(exit status 2): fatal error: runtime: out of memory
runtime stack:
runtime.throw(0x55a3a88c82cd, 0x16)
/usr/lib/golang/src/runtime/panic.go:1116 +0x74 fp=0x7ffed71f4140 sp=0x7ffed71f4110 pc=0x55a3a6ccfa74
runtime.sysMap(0xc000000000, 0x4000000, 0x55a3aa4bcdf8)
/usr/lib/golang/src/runtime/mem_linux.go:169 +0xc7 fp=0x7ffed71f4180 sp=0x7ffed71f4140 pc=0x55a3a6cb1347
runtime.(*mheap).sysAlloc(0x55a3aa4a0280, 0x400000, 0x0, 0x4)
/usr/lib/golang/src/runtime/malloc.go:727 +0x1d4 fp=0x7ffed71f4228 sp=0x7ffed71f4180 pc=0x55a3a6ca4af4
runtime.(*mheap).grow(0x55a3aa4a0280, 0x1, 0x0)
/usr/lib/golang/src/runtime/mheap.go:1344 +0x85 fp=0x7ffed71f4290 sp=0x7ffed71f4228 pc=0x55a3a6cc09a5
runtime.(*mheap).allocSpan(0x55a3aa4a0280, 0x1, 0x37312d7069002a00, 0x55a3aa4bce08, 0x2e3263652e393631)
/usr/lib/golang/src/runtime/mheap.go:1160 +0x6b6 fp=0x7ffed71f4310 sp=0x7ffed71f4290 pc=0x55a3a6cc0756
runtime.(*mheap).alloc.func1()
/usr/lib/golang/src/runtime/mheap.go:907 +0x66 fp=0x7ffed71f4368 sp=0x7ffed71f4310 pc=0x55a3a6cfece6
runtime.(*mheap).alloc(0x55a3aa4a0280, 0x1, 0x4012a, 0x2200000003)
/usr/lib/golang/src/runtime/mheap.go:901 +0x85 fp=0x7ffed71f43b8 sp=0x7ffed71f4368 pc=0x55a3a6cbfc25
runtime.(*mcentral).grow(0x55a3aa4b3138, 0x0)
/usr/lib/golang/src/runtime/mcentral.go:506 +0x7c fp=0x7ffed71f4400 sp=0x7ffed71f43b8 pc=0x55a3a6cb0d1c
runtime.(*mcentral).cacheSpan(0x55a3aa4b3138, 0x55a3a6cfcdfa)
/usr/lib/golang/src/runtime/mcentral.go:177 +0x3e5 fp=0x7ffed71f4478 sp=0x7ffed71f4400 pc=0x55a3a6cb0aa5
runtime.(*mcache).refill(0x7fbb625e2108, 0x2a)
/usr/lib/golang/src/runtime/mcache.go:142 +0xa5 fp=0x7ffed71f4498 sp=0x7ffed71f4478 pc=0x55a3a6cb0445
runtime.(*mcache).nextFree(0x7fbb625e2108, 0x55a3aa48622a, 0x7fbb625e2108, 0xfffffffffffffff8, 0x7ffed71f4528)
/usr/lib/golang/src/runtime/malloc.go:880 +0x8d fp=0x7ffed71f44d0 sp=0x7ffed71f4498 pc=0x55a3a6ca538d
runtime.mallocgc(0x180, 0x55a3a93c9060, 0x7ffed71f4501, 0x7ffed71f45d0)
/usr/lib/golang/src/runtime/malloc.go:1061 +0x854 fp=0x7ffed71f4570 sp=0x7ffed71f44d0 pc=0x55a3a6ca5d94
runtime.newobject(0x55a3a93c9060, 0x55a3a6cfd9e0)
/usr/lib/golang/src/runtime/malloc.go:1195 +0x3a fp=0x7ffed71f45a0 sp=0x7ffed71f4570 pc=0x55a3a6ca623a
runtime.malg(0x8000, 0x0)
/usr/lib/golang/src/runtime/proc.go:3520 +0x33 fp=0x7ffed71f45e0 sp=0x7ffed71f45a0 pc=0x55a3a6cda773
runtime.mpreinit(0x55a3aa4862c0)
/usr/lib/golang/src/runtime/os_linux.go:340 +0x2f fp=0x7ffed71f4600 sp=0x7ffed71f45e0 pc=0x55a3a6ccc5ef
runtime.mcommoninit(0x55a3aa4862c0, 0xffffffffffffffff)
/usr/lib/golang/src/runtime/proc.go:663 +0xfa fp=0x7ffed71f4648 sp=0x7ffed71f4600 pc=0x55a3a6cd38da
runtime.schedinit()
/usr/lib/golang/src/runtime/proc.go:565 +0xa5 fp=0x7ffed71f46a0 sp=0x7ffed71f4648 pc=0x55a3a6cd3465
runtime.rt0_go(0x7ffed71f47a8, 0x3, 0x7ffed71f47a8, 0x0, 0x7fbb617e30ba, 0x0, 0x7ffed71f47a8, 0x300000000, 0x55a3a6d07340, 0x0, ...)
/usr/lib/golang/src/runtime/asm_amd64.s:214 +0x129 fp=0x7ffed71f46a8 sp=0x7ffed71f46a0 pc=0x55a3a6d07489
2021/07/21 02:45:40.200761 [INFO] Executing cleanup logic
2021/07/21 02:45:40.210767 [INFO] CommandService Response: {"status":"FAILURE","api_version":"1.0","results":[{"status":"FAILURE","msg":"Engine execution has encountered an error.","returncode":1,"events":[{"msg":"Instance deployment failed to build the Docker image. The deployment failed.","timestamp":1626835540,"severity":"ERROR"},{"msg":"Instance deployment failed. For details, see 'eb-engine.log'.","timestamp":1626835540,"severity":"ERROR"}]}]}