Hello everyone!
Could really use some help trying to figure this one out. The database we're using is Postgres 9.6.x
I'm trying to figure out the total number of accounts by looking up a "company domain" in the database, and then grouping that number by account id.
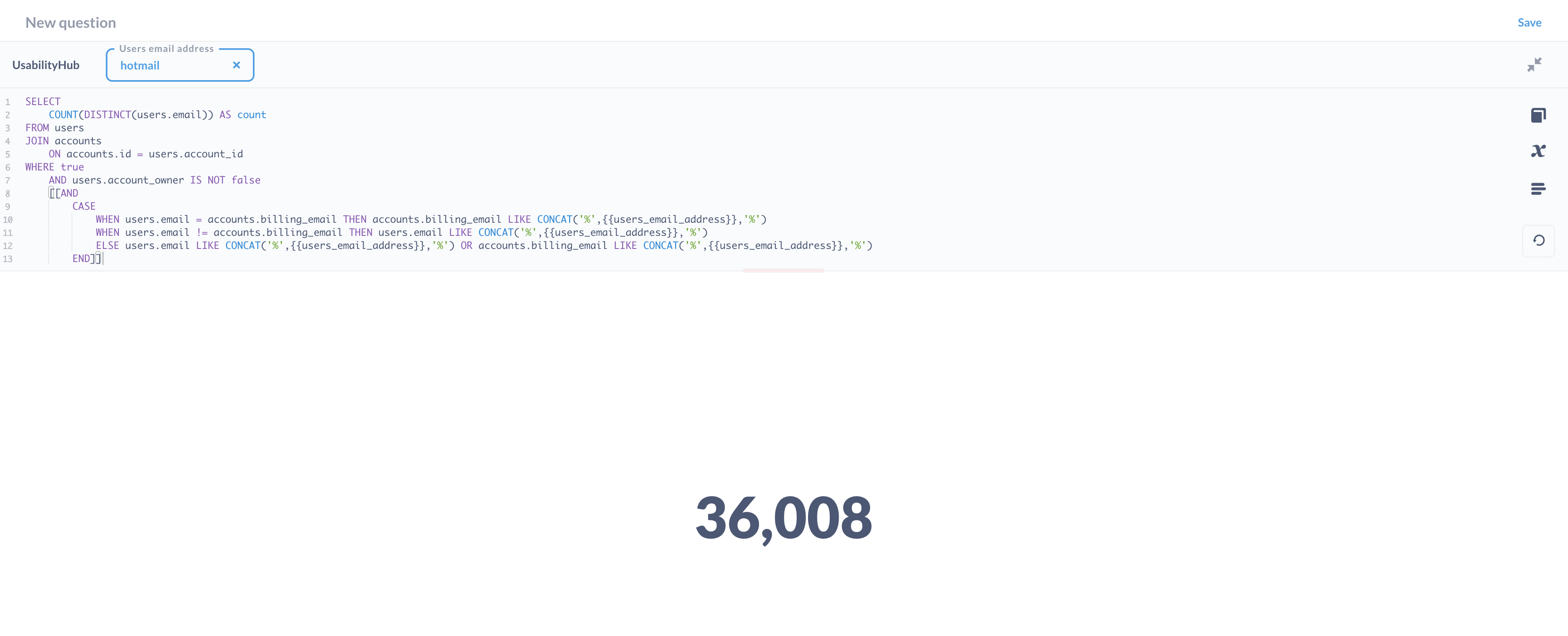
So, to start off, if I do a simple query that gives me the total number of accounts on that domain when I type in the domain into the text variable field.
SELECT
COUNT(DISTINCT(users.email)) AS count
FROM users
JOIN accounts
ON accounts.id = users.account_id
WHERE true
AND users.account_owner IS NOT false
[[AND
CASE
WHEN users.email = accounts.billing_email THEN accounts.billing_email LIKE CONCAT('%',{{users_email_address}},'%')
WHEN users.email != accounts.billing_email THEN users.email LIKE CONCAT('%',{{users_email_address}},'%')
ELSE users.email LIKE CONCAT('%',{{users_email_address}},'%') OR accounts.billing_email LIKE CONCAT('%',{{users_email_address}},'%')
END]]
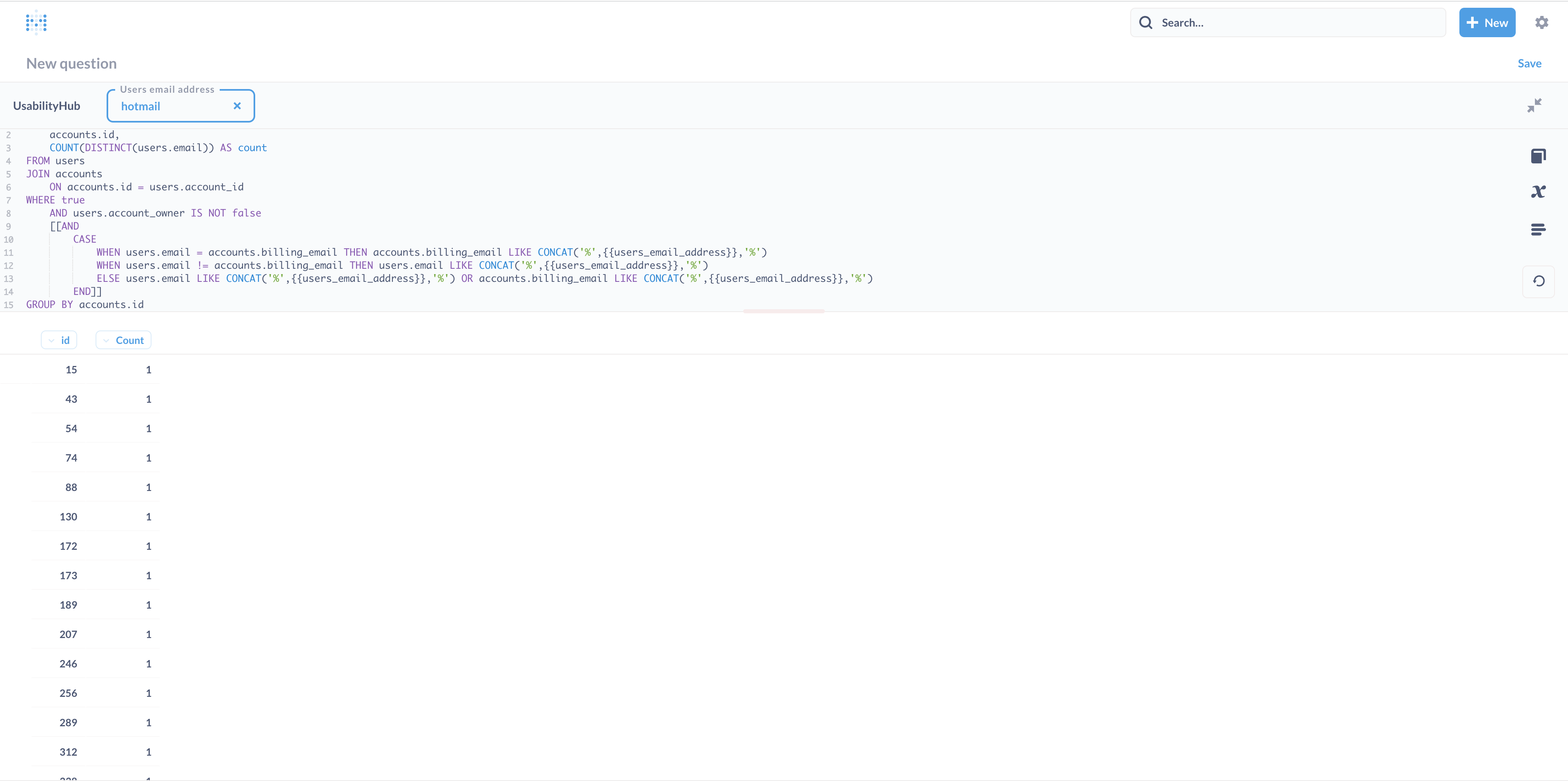
Now, if I want to group by account ID, I modify the query slightly so now I get a column with all the account ID's and the "Distinct Count" of the accounts on that domain in the other column, which of course works out to 1 for each domain, as such:
SELECT
accounts.id,
COUNT(DISTINCT(users.email)) AS count
FROM users
JOIN accounts
ON accounts.id = users.account_id
WHERE true
AND users.account_owner IS NOT false
[[AND
CASE
WHEN users.email = accounts.billing_email THEN accounts.billing_email LIKE CONCAT('%',{{users_email_address}},'%')
WHEN users.email != accounts.billing_email THEN users.email LIKE CONCAT('%',{{users_email_address}},'%')
ELSE users.email LIKE CONCAT('%',{{users_email_address}},'%') OR accounts.billing_email LIKE CONCAT('%',{{users_email_address}},'%')
END]]
GROUP BY accounts.id
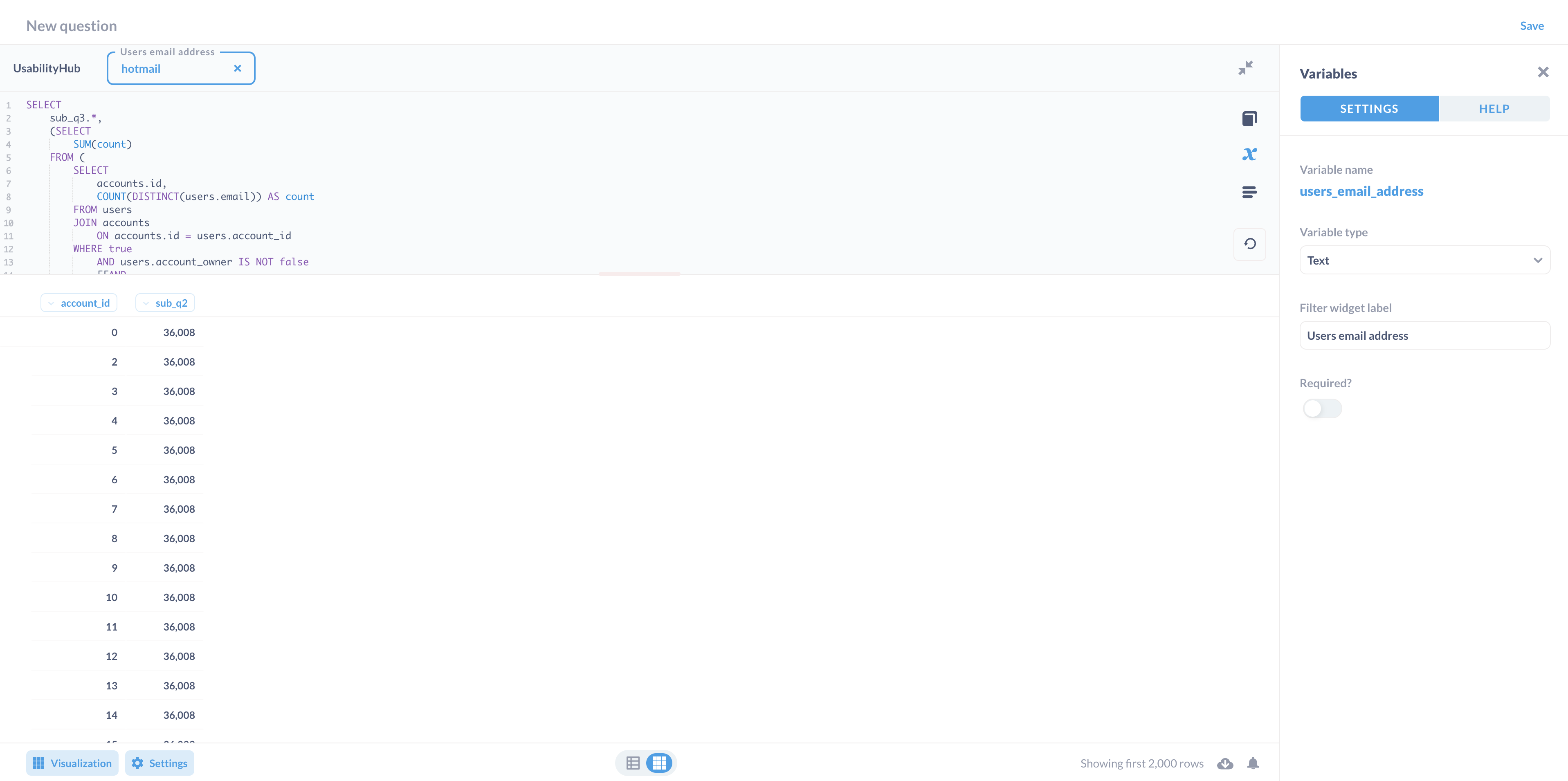
Ok, so basically, I want to show the SUM or the total for each domain, listed for every single account ID that matches, rather than the distinct values. I got close to doing this by modifying the query even further and using subqueries, but the problem is that even though the total appears on the second column, it's not filtering the matching account id's accordingly, and is instead showing that value to all account id's in the database.
SELECT
sub_q3.*,
(SELECT
SUM(count)
FROM (
SELECT
accounts.id,
COUNT(DISTINCT(users.email)) AS count
FROM users
JOIN accounts
ON accounts.id = users.account_id
WHERE true
AND users.account_owner IS NOT false
[[AND
CASE
WHEN users.email = accounts.billing_email THEN accounts.billing_email LIKE CONCAT('%',{{users_email_address}},'%')
WHEN users.email != accounts.billing_email THEN users.email LIKE CONCAT('%',{{users_email_address}},'%')
ELSE users.email LIKE CONCAT('%',{{users_email_address}},'%') OR accounts.billing_email LIKE CONCAT('%',{{users_email_address}},'%')
END
]]
GROUP BY accounts.id
) sub_q1
) sub_q2
FROM (
SELECT account_id
FROM users
GROUP BY account_id
) sub_q3
Any suggestions are greatly appreciated, thanks! ![]()