Platform: Bigquery
Overview:
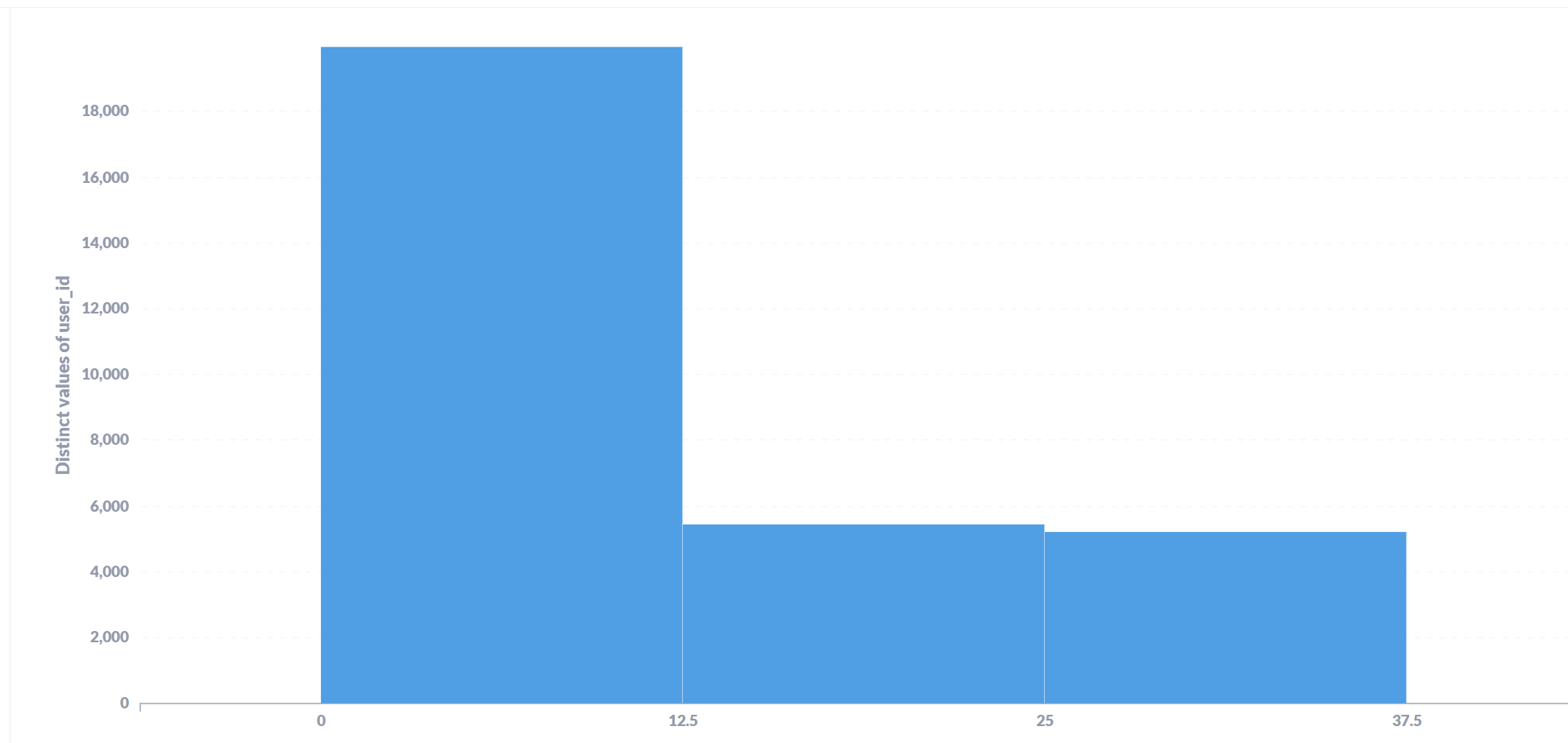
Previously, to resolve issues with nested aggregations not properly displaying in histogram format, We worked around this with a temporary question that we then aggregated on as per:
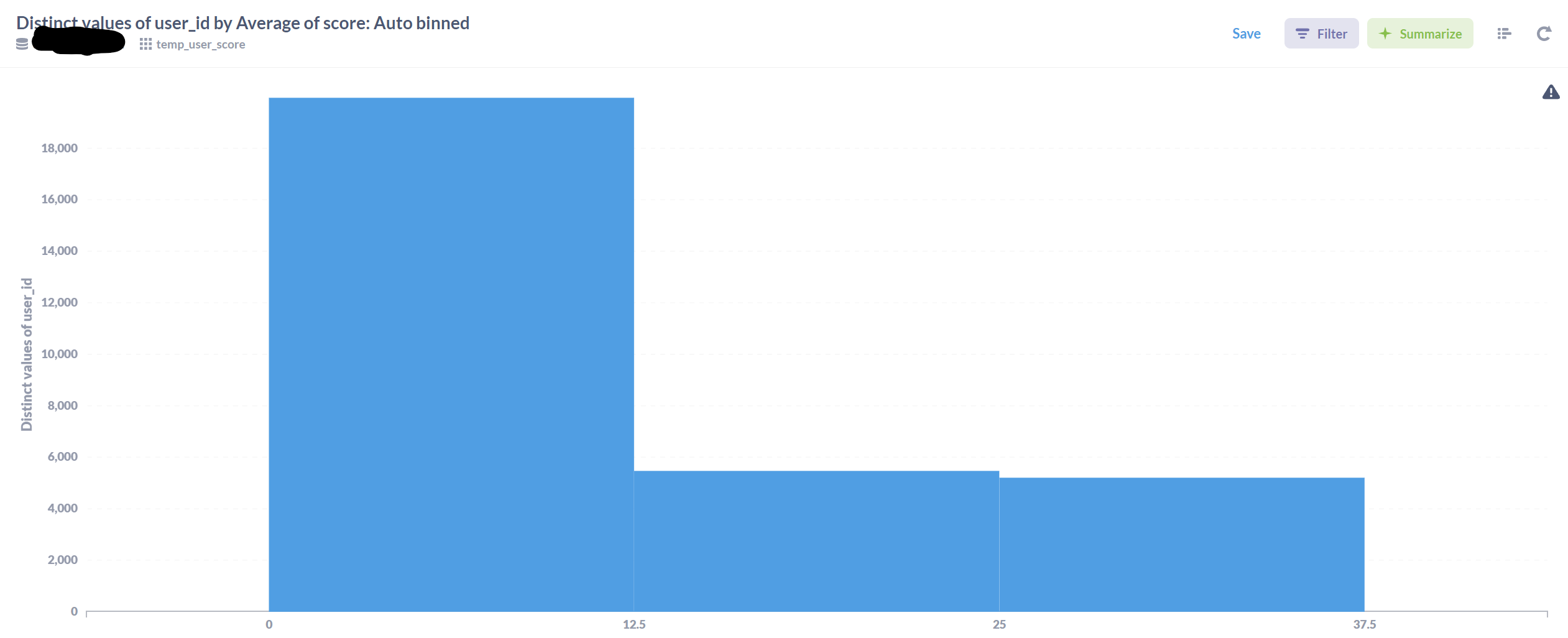
Attempting this again recently resulted in a histogram with only three bars, despite having data outside the presented range:
Note that values are definitely present above 37.5
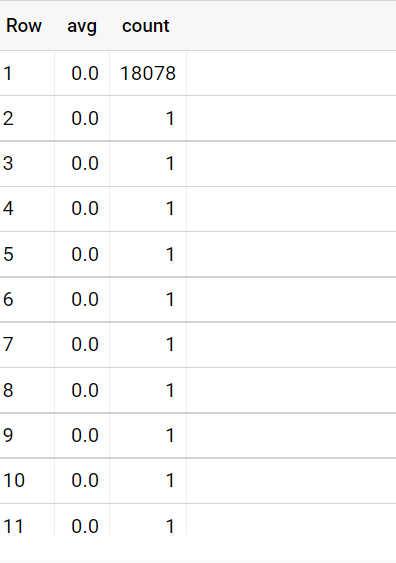
Running the generated SQL output in bigquery, we observed duplicated groupby columns with single counts, rather than the N columns we originally expected:
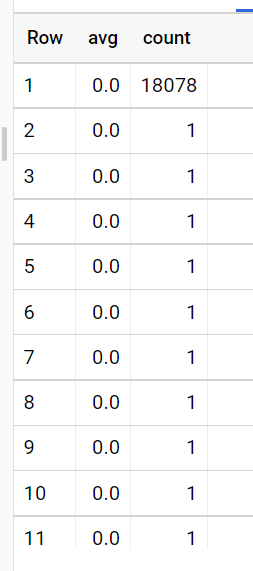
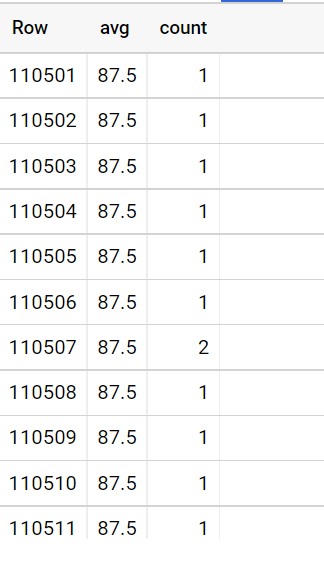
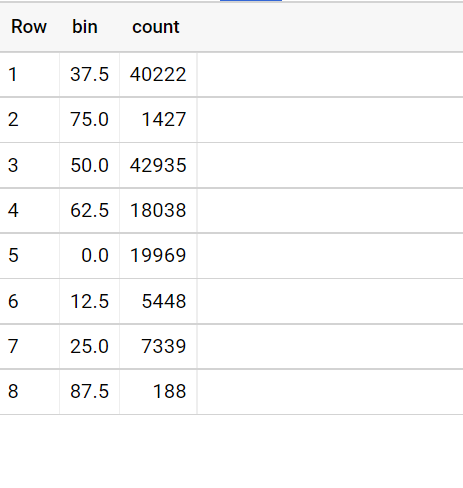
Currently, we've worked around this by preaggregating the data, but would like to know if this has already been observed. A quick check shows other binning issues, but none exactly like this.
Diagnostics:
{
"browser-info": {
"language": "en-GB",
"platform": "Win32",
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"vendor": "Google Inc."
},
"system-info": {
"file.encoding": "UTF-8",
"java.runtime.name": "OpenJDK Runtime Environment",
"java.runtime.version": "11.0.13+8",
"java.vendor": "Eclipse Adoptium",
"java.vendor.url": "https://adoptium.net/",
"java.version": "11.0.13",
"java.vm.name": "OpenJDK 64-Bit Server VM",
"java.vm.version": "11.0.13+8",
"os.name": "Linux",
"os.version": "4.14.219-164.354.amzn2.x86_64",
"user.language": "en",
"user.timezone": "GMT"
},
"metabase-info": {
"databases": [
"bigquery-cloud-sdk",
"bigquery"
],
"hosting-env": "unknown",
"application-database": "postgres",
"application-database-details": {
"database": {
"name": "PostgreSQL",
"version": "11.9"
},
"jdbc-driver": {
"name": "PostgreSQL JDBC Driver",
"version": "42.2.23"
}
},
"run-mode": "prod",
"version": {
"date": "2021-12-16",
"tag": "v1.41.5",
"branch": "release-x.41.x",
"hash": "fbfffc6"
},
"settings": {
"report-timezone": null
}
}
}```