Hi,
I might be running into the same issue mentioned in this issue: the search results in my self-hosted, open-source instance are regularly flushed. The re-init endpoint seems to partially fix the problem, as some results do reappear, however they’re still incomplete because some Questions just won’t show up.
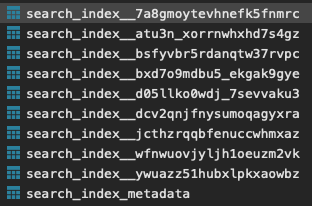
I have also noticed that there are several search_index__XXXxxxXXX tables in my Metabase db, that seem to come and go anew after new deployments/updates. They have between 13k and 19k rows.
Might there be a limit on the number of questions the search can handle? I currently have 13811 “not archived” rows in report_card for a grand total of 16031 rows.
I’m currently running 0.56.6.4 which is the latest and greatest 
Thanks for your help!
The search_index_metadata table contains information about the search_index__* tables. Can you post its contents? It might explain why a bunch of the indexes are hanging around.
In Admin → Tools → Jobs, there should be a listing for metabase.task.search-index.reindex.job. If you click the line, does the dialog that pops up show that it has been running?
Is there anything in the log from categories appdb.index and search.core? Is a line like this is logged? You should be getting one every hour or so.
INFO search.core :: Done reindexing in 2409ms (["table" 250] ["card" 179] ["dashboard" 26] ["dataset" 11] ["collection" 9] ["database" 8] ["action" 3] ["metric" 2]) {mb-quartz-job-type=SearchIndexReindex}
Are there any errors from the database, particularly around any queries like DROP TABLE search_index__*.
1 Like
Thank you for taking the time to reply!
Here’s the table’s content
As to the job, here’s what I can see:
As to your last two questions, I cannot see any of what you mentioned in either the MB or PG logs…
Do you think I should manually clear the search_index__* tables as well as the extra entries in search_index_metadata ?
Thanks again for your help
That index name with the strange version number looks suspicious. Is that when you ran the /reinit API call?
I’d shut down Metabase and delete that row & drop the related index table, leaving just one index as status ‘active’. Any search_index___* tables not listed in the metadata table can also be safely dropped.
Afterward, start Metabase back up and monitor the log to make sure the index runs are actually completing. If it isn’t able to complete in an hour, the two reindex jobs might be colliding. I assume the job scheduler keeps that from happening, but it may also indicate a problem with the index job, or the database itself.
Also keep an eye out for columns with strange values. It generally indicates a problem with the database storage.
1 Like