While in a discussion with AWS support, I was advised the following,
Please note that adding RDS instance as a part of EB environment is great for test environments, however it isn't ideal for a production environment because it ties the lifecycle of the database instance to the lifecycle of your application's environment which means if you terminate the environment, the database instance will be terminated as well.
But, from the Metabase documentation, I see the following:
The Metabase team runs a number of production installations on AWS using Elastic Beanstalk and currently recommend it as the preferred choice for production deployments.
We are currently running Metabase in a Test environment and would want to move to Production as soon as possible. So, I would like to know the real-world best practices for running Metabase in production and scaling that 100+ users.
It’s not really important how many users you have. It’s how many active sessions and how heavy the queries are, and which features of Metabase are being used.
That might be really difficult to answer until you go into production.
If you’re planning on running Metabase in EB for production purposes (we do), I’ve always separated the two, meaning not using the EB Configuration to create/provision the RDS instance.
Like @flamber said above, I’ve always created the RDS instances before (or used existing ones), and then configured Metabase (thru EB Environment config values) to connect/use that RDS instance.
@jpipas
I’m trying to do the same thing right but I’m having trouble finding where to set the env variables for the
docker image using the Benastalk configuration.
If I want to run a standalone docker image I would do something like this:
docker run -d -p 3000:3000
-e “MB_DB_TYPE=postgres”
-e “MB_DB_DBNAME=metabase”
-e “MB_DB_PORT=5432”
-e “MB_DB_USER=”
-e “MB_DB_PASS=”
-e “MB_DB_HOST=my-database-host”
–name metabase metabase/metabase
Create a RDS instance outside the beanstalk environment. So in case I terminate the Beanstalk enviornment the DB doesn’t get terminated.
Start the Beanstalk image using this as a reference and connect to the previously created database.
But to do that I have to tell the metabase instance where to connect to. How do I do that? I’m not sure sure if is a docker problem, beanstalk or both.
@fera320
Okay. Just create the RDS before creating the EBS, then they are not coupled - meaning when you destroy the EBS, then it will not destroy the RDS.
You still select the RDS to connect to, when you create the EBS. The setup in Metabase should be done automatically, since it gets the variables from the setup of EBS.
@flamber
I created the RDS instance. I launched the beanstalk application adding environment variables modifying the 01_metabase.config file but still is not working. When I connect I have a 502 gateway error. Not sure what I’m missing. Only other thing I had to do is change the URL so it doesn’t force me to setup the RDS instance, by changing the URL I mean when I launch this link I remove all the rds% query parameters.
This is how the 01_metabase.config file looks like (The container_commands section I left it as is)
@fera320
What do you see in the Metabase log (or EBS log)?
But if you have already recreated the RDS, then you should be able to connect to that instead of having the EBS create a new instance, from the EBS setup - without modifying any config.
Otherwise create the RDS from EBS, and then decouple it following the AWS guide: https://aws.amazon.com/premiumsupport/knowledge-center/decouple-rds-from-beanstalk/
Modify 01_metabase.config to include DB credentials based on step 1) (see post above for a sample). Zip file.
Launch the Beanstalk image following metabase documentation but remove querystring parameters related to rds so it doesn’t ask you to enter the values when lauching the environment.
The only think I don’t like about this is that the password shows in the config value but well.
@flamber Thanks for the help. If you see something that is not best practice let me know but this seems better than creating the RDS instance from beanstalk, detached and attach it again.
Thanks @fera320 for posting this for those of us looking to do the same thing, it helps allot.
Where in the Zip file are the querystring parameters in step 4?
That password issue, does it hang around in any way that could be exploited after all is said and done like in a stored rebuild or update file? If so can that be omitted or eliminated?
Any issues in doing this for MySQL rather than PostGres?
Where in the Zip file are the querystring parameters in step 4?
I'm talking about the AWS Console here. Just remove those parameters, I've been trying a lot of things so maybe this is not need it, you can play around with it, but after you change that you will notice that on the next screen beanstalk is no longer asking you to put the username and password for the RDS instance.
That password issue, does it hang around in any way that could be exploited after all is said and done like in a stored rebuild or update file? If so can that be omitted or eliminated?
That's the part I don't like about this. The password stays as a configuration variable on the beanstalk app. To avoid this you probably can encrypt it on S3 and read the values but you'll probably need to change the metabase code for deployment which I really don't want to do.
Here's an easy way and probably a more secure way to use an existing RDS outside of the EBS environment:
Prerequisites: spin up a Postgres RDS, SSH in via a Bastion EC2 instance, use SQL Workbench to tap the default database "postgres" and create an empty database called "metabase" (set automommit on; CREATE DATABASE metabase; set automommit off;).
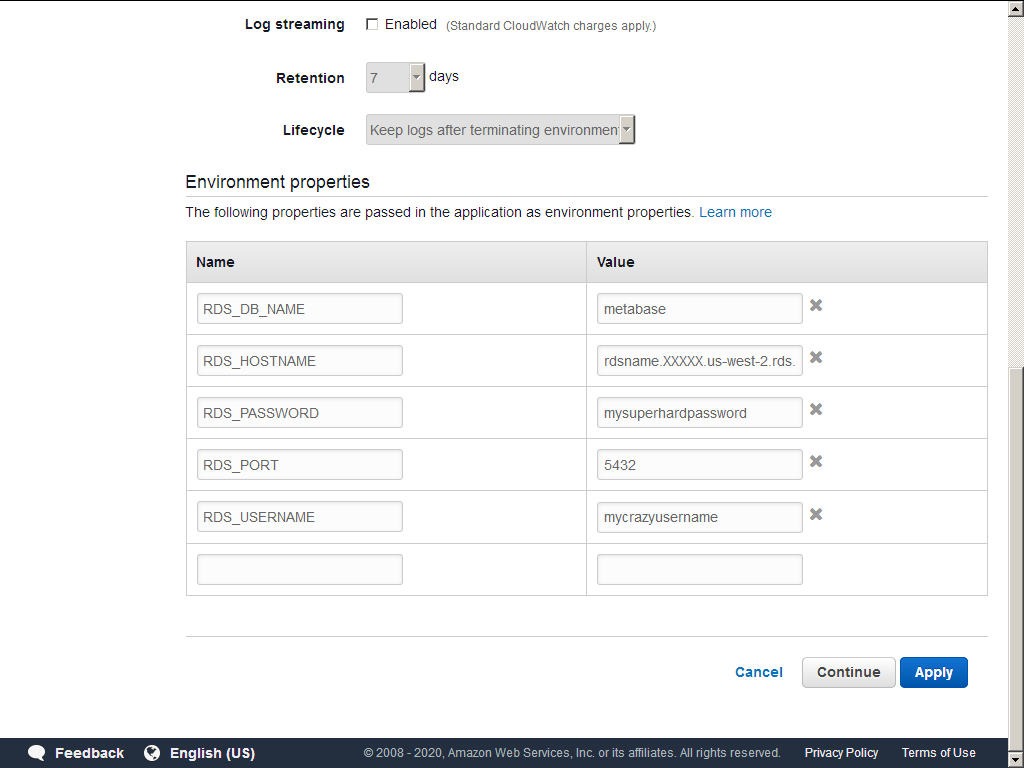
Create an EBS environment and using the "Configuring more options" selecting the "High availability" option modify Software>Environment properties (bottom) and fill in like so:
A very dated post from AWS support mentioned the defunct path EB Console: Configuration -> Web Layer -> Software Configuration and that was the critical clue on to how to this, the path is basically the same today! There must be some reference documentation about exactly this buried deep in the Amazon literature somewhere but no matter, this is the way to do it!
Best practice, plan ahead and use a non-EBS generated RDS from the get-go because doing it after the fact once an EBS environment contains an integrated EC2/RDS is inadvisable. Migrating from using the H2 database to MySQL or Postgres appears rather complicated in EBS as the EC2 instance jar file location is AMI dependent and that probably changes over time and with chosen configuration (SSH-ing in revealed absolutely nothing in my case). And Amazon's decoupling method sounds like a most painful proposition!
As for using MySQL rather than the zip's Postgres default, that would take editing at minimum the relevant JSON and other files to construct a custom image to draw from using Docker, Github, or some combination.
If anyone has done this or knows how to, please post, that would be a great resource!
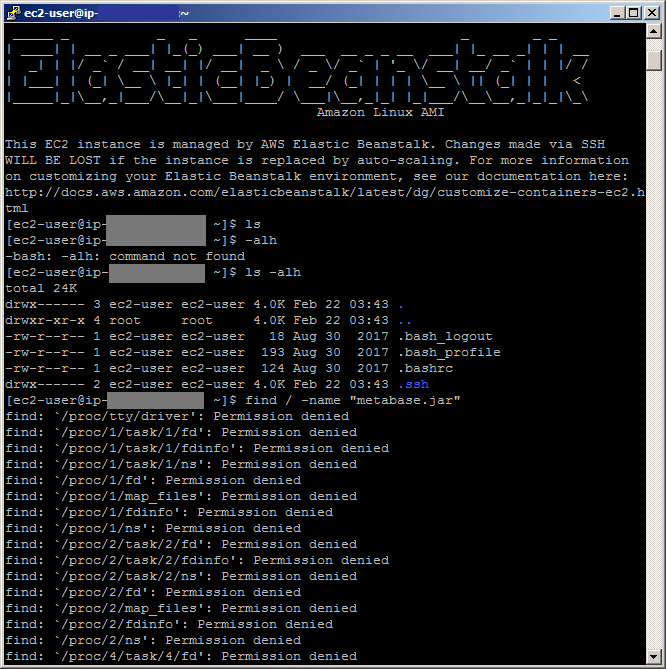
SSH-ing into the environment and bringing up hidden files & directories then searching for something familiar like "metabase.jar" is where I get lost, any idea how to proceed?
Sorry, just saw this.
I don’t remember SSHing to the instance, just generating the key locally (I might be wrong). I just followed the instructions from the link and added the secret key to the beanstalk config file:
Is this still best practice for creating a decoupled RDS instance? I have been running EBS/RDS coupled in production for the last 12 months and I really need to decouple so that I dont have a really bad day. I restored a copy of our production RDS Postgres DB. I then created a new ELB instance w/o a RDS Postrges instance. During creation I tried to configure so that it would attached to an existing DB, but it seemed I could only restore an existing backup or create a new DB, which I think puts me right back to where I am today with coupled ELB/RDS. So i created a new ELB w/o a DB. I then assumed I could go back in and point the newly created ELB to connect to my new RDS instance. No dice. Config in ELB still only provides options to restore or create a new DB.