ok so your problem is simply that the sync is killing your Metabase instance, either because there was some change in the data or simply because the sync + the normal usage of the instance is too much for the assigned resources. I would strongly suggest you change the sync process and move it to the night time or to a time your users don't use the server
Okay thank you, we have improved out servers capabilities, lowered the volume of questions being cached and changed the sync timings. Now spikes only hit 25% CPU utilisation even upon manual triggers of syncs. Will keep updated if it keeps crashing.
One question remains though and that is, what changed in the versions between 0.41.x and 0.48.x to require more demand on CPU and from the syncs?
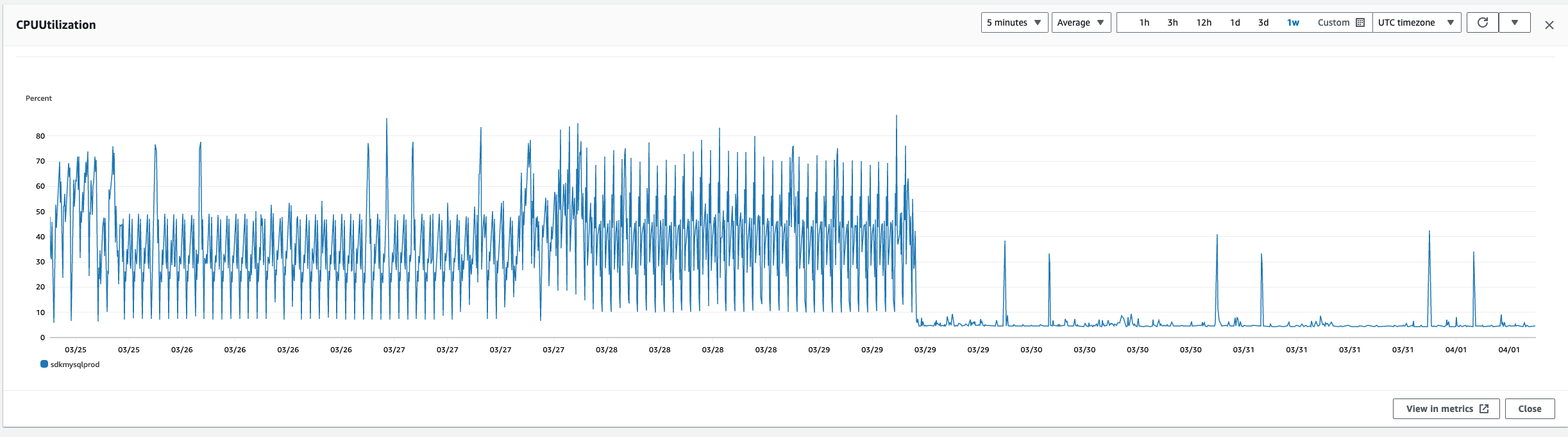
I want to throw one thing into this conversation. Our production database has been getting creamed of late with CPU spikes at or above 80% fairly routinely throughout the day. It reached a point in the last few weeks that writes to the DB were stalling out at least every other day during peak usage. We finally enabled a read replica and pointed out metabase instance at it and you can see what happened.
A bit about our setup:
- Running metabase on prem (47.4)
- Pro license
- Database is MySQL RDS on an M5.Large instance
- Metabase caching is enabled (settings below. we probably could have spent more time tuning this)
The one thing that is probably unique about our set up is we have about 20 different database connections configured in Metabase pointing out different subsets of tables on the MySQL instance. In total probably hitting ~200 tables. Refactoring this to use one database connection and then using users / groups in metabase maybe could have helped out? I'm honestly not sure.
TL;DR if you're seeing CPU spikes, a read replica might be an option for you.
Metabase does not support read/write splitting. You just made your Metabase read only and now every operation will be queued on RAM as it needs to write to the database at some point.
Please don’t do that and don’t recommend that never ever, Metabase needs to write to a database on its day to day operations
I'm not talking about the metabase database. We haven't touched that. I'm talking about the production database where the data comes from. Maybe I'm misunderstanding something here?
Please send the logs of Metabase when you saw the spikes on the database. If the connection is a DW then it should be the exact same pattern or otherwise you're denying some operation on the RR and your logs should be filled with errors
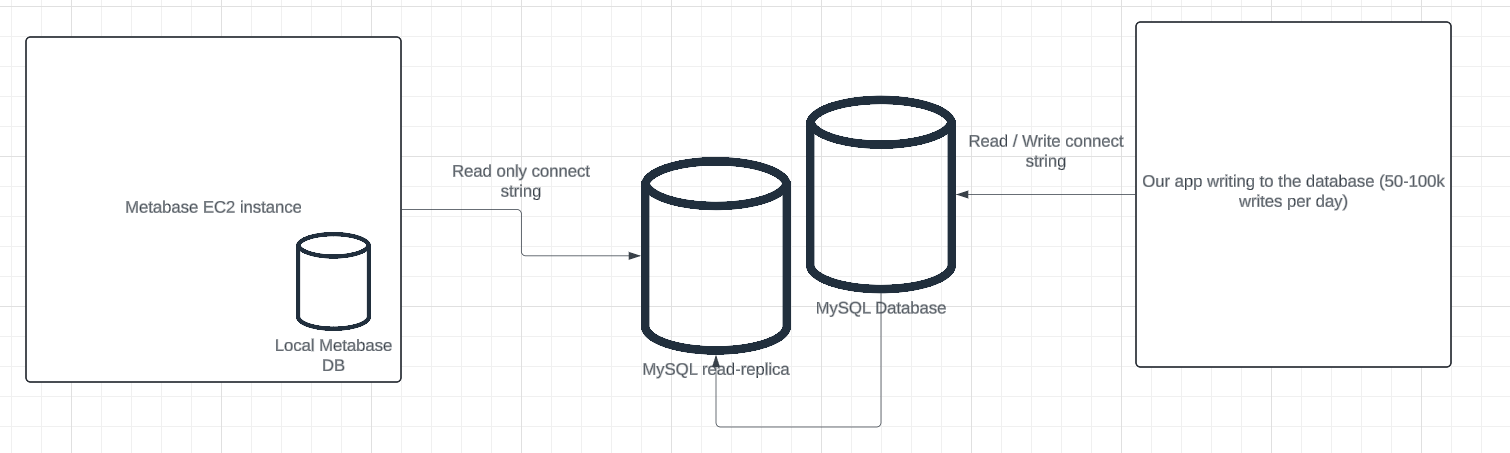
I see your point. Yes, the RR is now bearing the brunt of the load. Which is preferable to the main instance bearing it b/c it was occasionally affecting our ability to write to the database. See a very simplified version of how we have it set up now
How far back do the logs go? Since we stood up the RR we're seeing far fewer database errors in the metabase console. The logs there are only showing today's logs.
I would need to see the logs when the cpu spiked